“Books vs Bots: The Copyright Battle Brewing in India’s Courts”

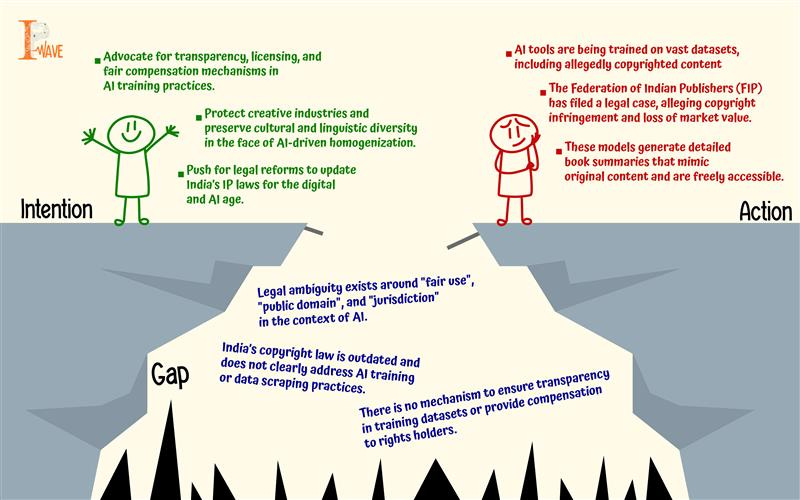
Delhi HC faces a modern dilemma, one that sets centuries-old publishers against silicon minds trained on vast oceans of data. The Federation of Indian Publishers (FIP), which speaks for the likes of Bloomsbury, Penguin Random House, Rupa Publications, and S. Chand & Co., has entered the legal battle, alleging that their copyrighted books have been mined without permission to train ChatGPT. According to FIP’s secretary Pranav Gupta, these AI-generated book summaries threaten their livelihoods. “If people can read precise summaries for free,” he warns, “why would they buy the book?”
It’s a question echoing in publishing houses and copyright offices across the globe. And it’s not just about India. Authors, musicians, journalists, and photographers from New York to Nairobi are asking the same thing: If artificial intelligence can be trained on our work without our permission, what value does this creativity still hold?
Who Owns the Data That Trains AI?
ChatGPT, like other large language models (LLMs), is trained on massive datasets scraped from websites, public forums, digitized books, and other online repositories. But frequently, that training includes copyrighted material, used without license or payment.
In the Indian lawsuit, the concern is focused on book summaries. ChatGPT, as of yet cannot reproduce full copyrighted books, but it can summarize them with close accuracy, from chapter by chapter to key plot twists and character arcs. These are not mere general impressions, they are structured outputs that, in the eyes of publishers, devalue the original content.
OpenAI, like other tech firms facing similar lawsuits, argue that the training involves "fair use" of publicly available data. But what counts as “publicly available” or “public domain” in the digital age? And more importantly, does “availability” imply “permission”.
A Global Conflict with Local Consequences
The Delhi High Court, where this lawsuit now sits, is one among several jurisdictions around the world where legal lines are being redrawn. In the United States, Stability AI and Midjourney have been sued by artists for training on copyrighted works. In the European Union, the AI Act suggests new transparency rules for training datasets. Canada and Australia are considering legislation requiring AI firms to disclose and license training materials.
India stands at a critical juncture. It is the world's most populous nation, with a booming digital economy, an emerging class of AI startups, and a rich tradition in publishing, journalism, and film. But its current intellectual property framework, which is largely based on the print and broadcast age, is not well equipped to manage these new frictions.
The Federation of Indian Publishers demand is threefold: end unauthorized access to content, release datasets, and give compensation or a license. In response, OpenAI has asserted immunity under the location of servers and U.S. legal standards. This gives rise to yet another pressing concern, which is jurisdiction. If an AI company based in California uses data originating in Delhi to train a model accessed by an Indian student in Mumbai, which country’s law should prevail?

The Digital Era’s Legal Vacuum
Copyright law was conceived in a world where copying involved physical reproduction of books, records, films. But the virtual world is more ambiguous. AI models such as ChatGPT do not keep books in a library or share them like a pirate website, it takes in patterns, imitates style, and produces new outputs.
Here, two things collapse. One is the boundary between public domain and copyrighted material, and the other is the distinction between use and reproduction. In the print world, these were clean lines. In the digital world, they are blurred.
What makes something “public”? Is a copyrighted book posted online without authorization “public domain”? Is scraping it an act of reading, copying, infringement or something else entirely?
Implications for Creativity and the Marketplace
This conflict goes beyond contracts and codes, it’s a battle over the future of human creativity. If AI tools, trained on millions of books, can summarize, rewrite, or even out-write original authors, what happens to incentives for writers, educators, and artists?
There is also the matter of market substitution. Publishers are afraid that free AI-generated summaries could eat into their book sales. This is especially critical in emerging economies, where digital platforms already dominate access to information and pirated material is common. For Indian publishers, where the market is price-conscious and linguistically diverse, losing even marginal sales could bring down entire business models.
And there is a cultural angle too. Indian publishers have long acted as stewards of regional literature, textbook authorship, and academic dissemination. The emergence of AI models that are trained on their content without supervision, threatens to produce a linguistic and literary monoculture based on English-centric, Silicon Valley-driven systems.
Why This Debate Matters Now
This case is a tectonic shift not just for India's judiciary, but for AI regulation globally. The Delhi High Court's ultimate ruling could set a precedent for the way AI services are operated in one of the world's biggest digital economies. It might spur legislative change, oblige AI companies to open up their training sets, and impose data licensing.
But more generally, it poses a fundamental question: In a time of smart machines, can legal framework help human creativity thrive and can physical products continue to safeguard imagination?
Human creativity has moved into a world where the distinction between original and derivative is algorithmically removed, and custodians of knowledge are not authors and editors but engineers and datasets. When the legal fog clears in India and elsewhere, the choices taken today will define the equation of innovation and intellectual property for generations to come.